Computational models for expression communication
Expressive Performance
 Effectively controlling expressiveness requires three different levels of abstraction. The control space is the user interface, which controls, at an abstract level, the expressive content and the interaction between the user and the multimedia product's audio object. To realize morphing among different expressive intentions, the audio-authoring tool works with two abstract control spaces. The first one, called perceptual expressive space, was derived by a multidimensional analysis of various professionally performed pieces ranging from western classical to popular music. The second, called synthetic expressive space, lets authors organize their own abstract space by defining expressive points and positioning them in the space. In this way, a certain musical expressive intention can be associated to the various multimedia objects. Therefore, the audio object changes its expressive intention, both when the user focuses on a particular multimedia object (by moving it with a pointer) and when the object itself enters the scene. Our tool permits receiving information from a multimedia object about its state and the author can exploit it for expressive control of audio. For instance, in a virtual environment the avatar can tell the system its intentions, which controls audio expressiveness. Thus, you can gain a direct mapping between the intentions of the avatar and audio expressiveness or a behavior chosen by the artist in the design step. With mapping strategies, users can vary the expressiveness (that is, morphing among happy, solemn, and sad), by moving inside the control space. Morphing can be realized with a wide range of graduality (from abrupt to very smooth), allowing the system to adapt to different situations.
Effectively controlling expressiveness requires three different levels of abstraction. The control space is the user interface, which controls, at an abstract level, the expressive content and the interaction between the user and the multimedia product's audio object. To realize morphing among different expressive intentions, the audio-authoring tool works with two abstract control spaces. The first one, called perceptual expressive space, was derived by a multidimensional analysis of various professionally performed pieces ranging from western classical to popular music. The second, called synthetic expressive space, lets authors organize their own abstract space by defining expressive points and positioning them in the space. In this way, a certain musical expressive intention can be associated to the various multimedia objects. Therefore, the audio object changes its expressive intention, both when the user focuses on a particular multimedia object (by moving it with a pointer) and when the object itself enters the scene. Our tool permits receiving information from a multimedia object about its state and the author can exploit it for expressive control of audio. For instance, in a virtual environment the avatar can tell the system its intentions, which controls audio expressiveness. Thus, you can gain a direct mapping between the intentions of the avatar and audio expressiveness or a behavior chosen by the artist in the design step. With mapping strategies, users can vary the expressiveness (that is, morphing among happy, solemn, and sad), by moving inside the control space. Morphing can be realized with a wide range of graduality (from abrupt to very smooth), allowing the system to adapt to different situations.
- MIDI: From Mozart K622 neutral to bright - dark - hard - soft - light - heavy.
- Post-processing: From Corelli Op. V neutral to bright - heavy - light - hard.
Gestural Control

Musical interpretations are often the result of a wide range of requirements on expressiveness rendering and technical skills. Aspects indicated by the term expressive intention and which refer to the communication of moods and feelings, are being considered more and more important in performer-computer interaction during music performance. Recent studies demonstrate the possibility of conveying different sensitive content like expressive intentions and emotions by opportunely modifying systematic deviations introduced by the musician. In our applications we use control strategies based on a multi-layer representation with three different stages of mapping, to explore the analogies between sound and movement spaces. The mapping between the performer (dancer and/or musician) movements and the expressive audio rendering engine resulting by two 3D "expressive" spaces, one obtained by the Laban and Lawrence's effort's theory, the other by means of a multidimensional analysis of perceptual tests carried out on various professionally performed pieces ranging from western classical to popular music. In figure, an application based on this model is presented: the system is developed using the eMotion SMART motion capture system and the Eyesweb software.
Expressive sound spatialization
 During the MEGA project one of the research goal of the group was to evaluate sound movement as a musical parameter and determine whether it has potential expressive content for the listener. A psychoacoustic test has been performed to establish a perceptive paradigm with which to construct a model for use in a musical context. This study focused on three parameters that are considered sound movement's basic components: speed, articulation, and path. The results of this study have been applied to the opera-video Medea by Adriano Guarnieri, premiered at the Palafenice of Venice in 2002.
Medea's score cites sound spatialization as a fundamental feature of the opera. The musicians
in the hall should be considered a sonic body living among the audience to create a sort of gravitational center for the trumpets located on either side of the audience. The presence of trombones with their gestural posture becomes a central expressive feature. The gesture expressiveness of the trombone players has been mapped in to coherent expressive sound movements in the virtual space, using the Eyesweb model developed.
During the MEGA project one of the research goal of the group was to evaluate sound movement as a musical parameter and determine whether it has potential expressive content for the listener. A psychoacoustic test has been performed to establish a perceptive paradigm with which to construct a model for use in a musical context. This study focused on three parameters that are considered sound movement's basic components: speed, articulation, and path. The results of this study have been applied to the opera-video Medea by Adriano Guarnieri, premiered at the Palafenice of Venice in 2002.
Medea's score cites sound spatialization as a fundamental feature of the opera. The musicians
in the hall should be considered a sonic body living among the audience to create a sort of gravitational center for the trumpets located on either side of the audience. The presence of trombones with their gestural posture becomes a central expressive feature. The gesture expressiveness of the trombone players has been mapped in to coherent expressive sound movements in the virtual space, using the Eyesweb model developed.
Automatic Analysis of Expressive Content
Expressive Classifiers
 At SMC-CSC several experiments were conducted to classify the expressive content of both known pieces and improvisations. The data were recorded into MIDI files, then several perceptual and acoustical analysis were carried out in order to extract models. The realized analysis models are based on studies on synthesis and analysis of musical improvisations. The synthesis model was described can synthesize an expressive performance by transforming a neutral one (i.e. a literal human performance of the score without any expressive intention or stylistic choice), referencing to a given score. The transformation is carried out taking into account how listeners organize expressive performances in their mind. By the perceptual test a "Perceptual Parametric Space" (PPS) was obtained, in which the expressive labels were placed. It was found that the two axis of the space are closely related to physical acoustic quantities, respectively the kinetics (tempo and legato values) of the music (bright vs. dark), and the energy (loudness) of the sound (soft vs. hard). Thus, the micro deviations of acoustic quantities are computed by transforming those that are already present in the neutral performance. The transformations are applied to the various acoustic quantities (tempo, legato, and intensity) by means of two sets of coefficients named K-coefficients and M-
coefficients: a K-coefficients changes the average values of an acoustic quantity, and the respective M-coefficients is used to scale the deviations of the actual values of the same parameter from the average.
At SMC-CSC several experiments were conducted to classify the expressive content of both known pieces and improvisations. The data were recorded into MIDI files, then several perceptual and acoustical analysis were carried out in order to extract models. The realized analysis models are based on studies on synthesis and analysis of musical improvisations. The synthesis model was described can synthesize an expressive performance by transforming a neutral one (i.e. a literal human performance of the score without any expressive intention or stylistic choice), referencing to a given score. The transformation is carried out taking into account how listeners organize expressive performances in their mind. By the perceptual test a "Perceptual Parametric Space" (PPS) was obtained, in which the expressive labels were placed. It was found that the two axis of the space are closely related to physical acoustic quantities, respectively the kinetics (tempo and legato values) of the music (bright vs. dark), and the energy (loudness) of the sound (soft vs. hard). Thus, the micro deviations of acoustic quantities are computed by transforming those that are already present in the neutral performance. The transformations are applied to the various acoustic quantities (tempo, legato, and intensity) by means of two sets of coefficients named K-coefficients and M-
coefficients: a K-coefficients changes the average values of an acoustic quantity, and the respective M-coefficients is used to scale the deviations of the actual values of the same parameter from the average.
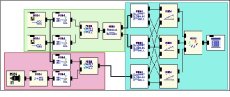
 Concerning analysis using the score knowledge, we made the implementation of the model using EyesWeb. We developed a number of new blocks that implement dedicated functions and we connected them in a patch for the real time analysis of a performance. Figure on the top shows the patch that analyzes the pieces using the score knowledge (Expressive Analyzer). On the other side, analysis of expressive content without the score knowledge was carried out by means of statistical techniques in order to analyze real time improvisations. A set of improvisations were recorded and analyzed to infer both a Bayesian network (see figure in the bottom) and a set of HMMs able to give as output the probability that the input performance is played according to an expressive intention.
Concerning analysis using the score knowledge, we made the implementation of the model using EyesWeb. We developed a number of new blocks that implement dedicated functions and we connected them in a patch for the real time analysis of a performance. Figure on the top shows the patch that analyzes the pieces using the score knowledge (Expressive Analyzer). On the other side, analysis of expressive content without the score knowledge was carried out by means of statistical techniques in order to analyze real time improvisations. A set of improvisations were recorded and analyzed to infer both a Bayesian network (see figure in the bottom) and a set of HMMs able to give as output the probability that the input performance is played according to an expressive intention.
Analysis of Expression on Audio Data
 During a music performance, the musician adds expressiveness to the musical message by changing timing, dynamics, and timbre of the musical events to communicate an expressive intention. Traditionally, the analysis of music expression is based on measurements of the deviations of the
acoustic parameters with respect to the written score. These works use similar approaches based on the knowledge of the score, but it is not advisable in practical applications since it excludes musical improvisation or many non-western musical
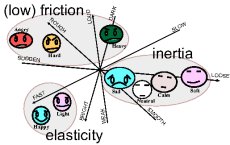
forms and score following is difficult. In this research area we employ machine learning techniques to understand the expressive communication and to derive audio features at an intermediate level, between music intended as a structured language and notes intended as sound at a more physical level. We started by extracting audio features from expressive performances played with various instruments, where expressions were inspired by adjectives both from affective and sensorial domains. By Sequential Forward Selection and Principal Component Analysis we derived a set of features for a general description of the expressions, and a set of descriptors specific for each instrument. We finally trained a Naive Bayesian classifier in order to test the features, and we found that higher recognition ratings were achieved by using a set of four features which can be specifically related to qualitative descriptions of the sound by physical metaphors. Thus we exploited the significance of the selected features in order to see how all the adjectives are jointly organized in the feature space, and to explain the found relations relating the space to a semantic interpretation and possible association among sensorial and affective labels. Three main cluster emerged: Hard/Heavy/Angry, Sad/Calm/Soft/ and Light/Happy. These audio features can be used to retrieve expressive content on audio data, and to design a next generation of search engines for Music Information Retrieval.
During a music performance, the musician adds expressiveness to the musical message by changing timing, dynamics, and timbre of the musical events to communicate an expressive intention. Traditionally, the analysis of music expression is based on measurements of the deviations of the
acoustic parameters with respect to the written score. These works use similar approaches based on the knowledge of the score, but it is not advisable in practical applications since it excludes musical improvisation or many non-western musical
forms and score following is difficult. In this research area we employ machine learning techniques to understand the expressive communication and to derive audio features at an intermediate level, between music intended as a structured language and notes intended as sound at a more physical level. We started by extracting audio features from expressive performances played with various instruments, where expressions were inspired by adjectives both from affective and sensorial domains. By Sequential Forward Selection and Principal Component Analysis we derived a set of features for a general description of the expressions, and a set of descriptors specific for each instrument. We finally trained a Naive Bayesian classifier in order to test the features, and we found that higher recognition ratings were achieved by using a set of four features which can be specifically related to qualitative descriptions of the sound by physical metaphors. Thus we exploited the significance of the selected features in order to see how all the adjectives are jointly organized in the feature space, and to explain the found relations relating the space to a semantic interpretation and possible association among sensorial and affective labels. Three main cluster emerged: Hard/Heavy/Angry, Sad/Calm/Soft/ and Light/Happy. These audio features can be used to retrieve expressive content on audio data, and to design a next generation of search engines for Music Information Retrieval.
Research Threads
3D Audio
Audio in multimodal interfaces
Audio restoration
Interactive environments for learning
Music expression modeling
Physically-based sound modeling
Virtual rehabilitation
History of CSC research
Sub-Threads
Expressive Performances
Gestural Control
Expressive Classifiers
Analysis of Expression
Expressive sound spatialization
Projects
A complete list of projects and industrial partners can be found here.